在人工智能快速发展的浪潮中,自然语言处理领域迎来了一项重大突破。近日,一家领先的AI研究机构宣布成功开发出一种新型语言模型,该模型通过自监督训练方式,在不依赖人工标注数据的情况下实现了多项先进功能。这一进展不仅展示了AI技术的潜力,还可能改写现有模型的训练标准。
该模型是一种大型系统,利用海量网络文本数据进行自我监督学习。简单来说,它通过预测和填补缺失的信息来“阅读”大量文本,从而生成连贯且逻辑合理的段落。研究人员表示,这项工作基于深度学习框架,并在多个标准化测试中取得了领先结果,挑战了传统监督学习方法的局限性。具体而言,在语言模型基准上,如困惑度评估(perplexity)任务中,该系统的表现已达到当前最佳水平。
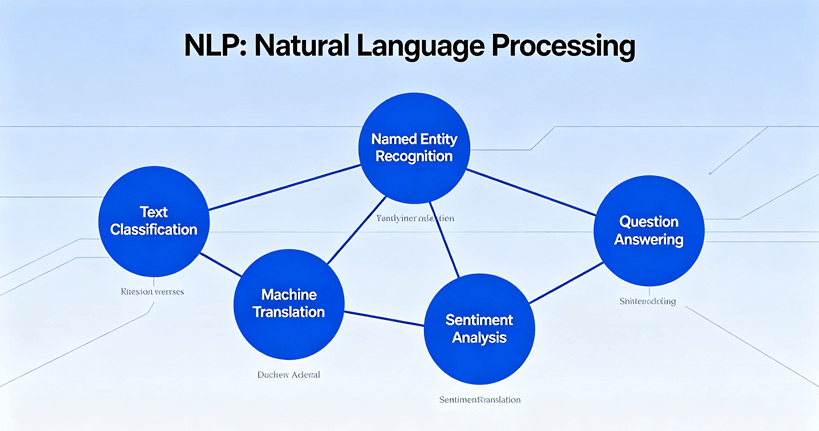
在实际应用方面,这款模型无需针对特定任务进行额外优化就能执行基本的阅读理解。这意味着,在面对用户查询或文本时,它可以自动分析并提供简要解释或答案,而无需像现有技术那样耗费大量时间和资源进行微调。此外,在机器翻译领域,它能够将英语文本准确转换为其他语言;在问答系统中,则能基于输入生成相关回复,展示出一定的知识覆盖能力。同时,它还能进行文本总结,将长篇文章浓缩为简洁摘要。
为了更好地理解这一进展,我们回顾一下AI语言模型的发展历程。过去十年中,这类模型已成为自然语言处理的基石之一,得益于像BERT(Bidirectional Encoder Representations from Transformers)、GPT-3这样的开创性工作。这些模型通常通过监督学习结合大量数据来提高性能,但它们也面临一些挑战:例如,训练过程可能涉及敏感信息处理,并且在特定任务上需要人工干预以提升准确性。相比之下,这款新模型采用了完全不同的路径——它仅依赖未标记的数据进行训练,这类似于一门语言学习者通过阅读和写作来掌握技能,而无需老师逐句指导。
这一创新在AI行业中具有深远意义。首先,在效率方面,传统模型如BERT往往需要数周时间来微调以防错误或偏见放大,而这款未监督模型在初始训练后就能直接处理多样化任务。这可能会降低开发成本,尤其对于小型企业来说,他们可以更容易地构建AI应用而不需庞大的计算资源。其次,在可扩展性上,它为处理大规模数据提供了新思路,可能在教育、医疗或商业分析等领域发挥作用。例如,在疫情期间,类似模型可以帮助快速翻译卫生指南或总结研究报告,从而加速决策过程。
然而,我们也需要谨慎看待。尽管它在基准测试中表现出色,但在真实世界应用中,这款模型可能仍然存在局限性。比如,在阅读理解任务上,它虽然能生成初步答案,但或许无法捕捉复杂的上下文或细微差别,这可能导致误导性输出。此外,潜在的公平性和偏见问题不容忽视——既然模型是基于互联网数据自主学习的,它可能会无意中强化某些刻板印象或传播不准确信息。这些问题在AI社区中已经广泛讨论,因此这款模型的出现需要更多研究来完善。
总体而言,这款未监督语言模型的开发标志着AI从手工优化向自动化转变的趋势更加明显。它不仅提升了研究者对模型鲁棒性的认知,还可能激发更多未监督学习算法的探索。展望未来,随着计算能力的增强和数据伦理规范的推出,预计这一技术会在2024年后的深度学习竞赛中占据一席之地。
这一事件无疑将推动全球AI产业的变革。业界专家正在密切关注其性能对比现有系统如ChatGPT [聊天机器人 GPT],那些模型也依赖监督训练,而这款新模型可能成为开源AI领域的标杆之一。总之,在语言模型的进化史上,这是一项值得称赞的成就。

